
从“队列优先”到“线程优先”:一次对ThreadPoolExecutor工作模式的深度定制与思考
默认模式的“佛系”与业务场景的“激进”
今天想和大家分享一个最近在华为云看到的一篇文章内容,颇为有趣:“调教”Java线程池。
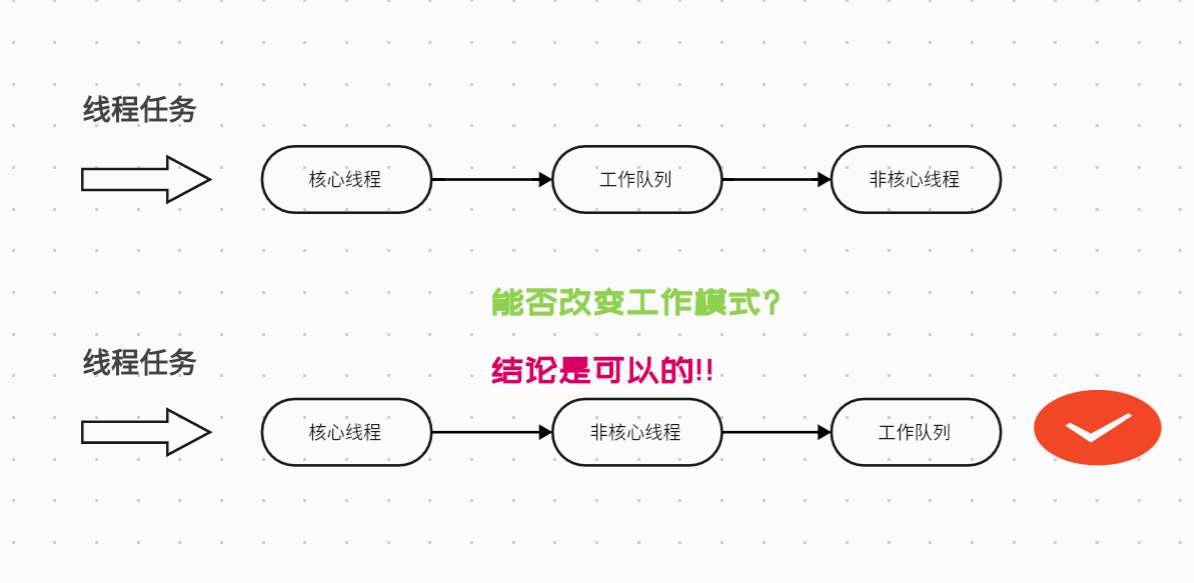
我们都知道,Java的ThreadPoolExecutor是个“老好人”,它有一套默认的、非常稳健的工作流程,我称之为 “佛系三步走”:
- 核心接待:任务来了,先看看核心线程池有没有空位,有就接着。
- 排队等候:核心线程忙?别急,去工作队列里取个号,老实排队。
- 紧急扩容:队都排满了?这时候才启动“应急预案”,创建非核心线程来帮忙。
- 拒绝服务:如果连“应急线程”都用完了,对不起,只能按拒绝策略处理了。
这套逻辑在绝大多数场景下非常合理,优先排队,避免无节制的线程创建。但我在处理一个高并发、低延迟的实时数据处理模块时,却发现它成了瓶颈。但是有的业务特点是:任务执行时间短,但对响应延迟极其敏感。让任务在队列里等待,哪怕几毫秒,都是不可接受的。
这种业务要的,是一种更“激进”的模式:
榨干所有可用线程(核心 -> 非核心)之后,才考虑让任务去排队。
这听起来像是要颠覆线程池的设计哲学。但是有一个个优雅(或者说有点“狡猾”)的解决方案。下面是我的探索之旅。
一、破局关键:“欺骗”队列的offer方法
ThreadPoolExecutor决定是否创建非核心线程,关键在于一个判断:“队列满了吗?” 如果队列说“我没满”,线程池就让任务去排队;如果队列说“我满了”,线程池才会考虑动用非核心线程。
那么,如果我们能让队列从一开始就说“我满了”呢?
这就是整个方案的核心思想。我们自定义一个队列,重写它的offer方法,让它永远返回false。这样,线程池会误以为队列已满,从而跳过排队阶段,直接尝试创建非核心线程。
public class TrickQueue extends LinkedBlockingQueue<Runnable> {
@Override
public boolean offer(Runnable runnable) {
// 永远对线程池说:“队列已满,别往里放了!”
return false; // 关键的“谎言”
}
// 但我们提供一个“后门”,真正存放任务的方法
public boolean realOffer(Runnable runnable) {
System.out.println(Thread.currentThread().getName() + " :: 任务**真正**进入队列");
return super.offer(runnable); // 调用父类真正的入队方法
}
}
二、闭环设计:自定义拒绝策略,完成“兜底”
仅仅欺骗是不够的。当核心和非核心线程都用尽后,线程池会执行拒绝策略。如果直接抛出异常,任务就丢失了。
所以,我们需要一个“配套的谎言”:自定义拒绝策略。在这个策略里,我们不再拒绝任务,而是把它悄悄地塞回那个一直说“自己满了”的队列里。至此,我们想要的工作流就完整了。
public class RescuePolicy implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println(Thread.currentThread().getName() + " :: 触发**兜底**拒绝策略!");
// 关键一步:此时才真正将任务放入队列
if (executor.getQueue() instanceof TrickQueue) {
((TrickQueue) executor.getQueue()).realOffer(r);
}
}
}
三、完整实现:组装我们的“激进线程池”
现在,我们把“骗子队列”和“兜底策略”组合起来,创建一个行为独特的线程池。
public class AggressiveThreadPoolDemo {
public static void main(String[] args) throws InterruptedException {
TrickQueue trickQueue = new TrickQueue();
ThreadPoolExecutor aggressivePool = new ThreadPoolExecutor(
2, // 核心线程数
5, // 最大线程数(核心2 + 非核心3)
60, TimeUnit.SECONDS,
trickQueue, // 使用我们的“骗子队列”
new NamedThreadFactory(), // 自定义线程工厂,方便观察
new RescuePolicy() // 使用我们的“兜底策略”
);
// 提交15个任务,观察执行顺序
for (int i = 1; i <= 15; i++) {
final int taskId = i;
aggressivePool.execute(() -> {
try {
System.out.println(String.format("[%s] 正在执行任务 Task-%02d | 活跃线程数:%d",
Thread.currentThread().getName(),
taskId,
aggressivePool.getActiveCount()));
Thread.sleep(1000); // 模拟任务执行
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
Thread.sleep(100); // 稍微间隔,方便观察输出顺序
}
aggressivePool.shutdown();
}
}
// 一个简单的命名线程工厂
class NamedThreadFactory implements ThreadFactory {
private final AtomicInteger threadCount = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
int count = threadCount.getAndIncrement();
String type = count <= 2 ? "Core" : "NonCore";
return new Thread(r, type + "-Thread-" + count);
}
}
四、运行观察:见证“谎言”的力量
运行上述代码,你会看到类似如下的输出:
i = 1
poolExecutor.getPoolSize() = 1
核心线程 ( 1 ) :: 执行 1
i = 2
poolExecutor.getPoolSize() = 2
核心线程 ( 2 ) :: 执行 2
i = 3
main :: 尝试进入队列 当前队列元素个数 :0
poolExecutor.getPoolSize() = 3
非核心线程 ( 1 ) :: 执行 3
i = 4
main :: 尝试进入队列 当前队列元素个数 :0
poolExecutor.getPoolSize() = 4
非核心线程 ( 2 ) :: 执行 4
i = 5
main :: 尝试进入队列 当前队列元素个数 :0
poolExecutor.getPoolSize() = 5
非核心线程 ( 3 ) :: 执行 5
i = 6
main :: 尝试进入队列 当前队列元素个数 :0
poolExecutor.getPoolSize() = 6
非核心线程 ( 4 ) :: 执行 6
i = 7
main :: 尝试进入队列 当前队列元素个数 :0
poolExecutor.getPoolSize() = 7
非核心线程 ( 5 ) :: 执行 7
i = 8
main :: 尝试进入队列 当前队列元素个数 :0
poolExecutor.getPoolSize() = 8
非核心线程 ( 6 ) :: 执行 8
i = 9
main :: 尝试进入队列 当前队列元素个数 :0
poolExecutor.getPoolSize() = 9
非核心线程 ( 7 ) :: 执行 9
i = 10
main :: 尝试进入队列 当前队列元素个数 :0
poolExecutor.getPoolSize() = 10
非核心线程 ( 8 ) :: 执行 10
i = 11
main :: 尝试进入队列 当前队列元素个数 :0
main :: 触发拒绝策略
main :: 真正进入队列 当前队列元素个数 :1
i = 12
main :: 尝试进入队列 当前队列元素个数 :1
main :: 触发拒绝策略
main :: 真正进入队列 当前队列元素个数 :2
i = 13
main :: 尝试进入队列 当前队列元素个数 :2
main :: 触发拒绝策略
main :: 真正进入队列 当前队列元素个数 :3
...
清晰的工作流:
- 任务1、2:由两个核心线程立即执行。
- 任务3、4、5:队列“说谎”已满,线程池依次创建3个非核心线程来执行。
- 任务6及以后:核心和非核心线程(共5个)都已占满,触发拒绝策略。拒绝策略作为“后手”,将任务真正放入队列等待。
目标达成! 我们成功地将线程池的工作模式从 核心 -> 队列 -> 非核心,改造为了 核心 -> 非核心 -> 队列。
五、深度思考:何时该用,何时慎用?
这种模式虽然巧妙,但绝不是银弹,它是对标准模型的“魔改”。在决定使用前,请务必想清楚:
适用场景:
- 低延迟、高优先级任务:需要尽可能快地开始执行,无法容忍队列等待。
- 任务执行时间极短:线程上下文切换开销相对可控,快速创建线程处理完即销毁。
- 作为特定资源隔离策略:确保某些关键任务总能获得线程资源。
风险与代价:
- 线程爆炸风险:如果任务提交速度持续高于处理速度,会瞬间创建大量非核心线程,耗尽系统资源。
- 破坏线程池设计初衷:标准模型用队列做缓冲,是为了平滑突发流量、保护系统稳定性。本方案牺牲了这层缓冲。
- 可能加剧锁竞争:更多线程同时竞争共享资源,可能引发性能下降。
建议:
- 务必设置合理的maximumPoolSize,并配合良好的监控(如线程数、队列大小)。
- 考虑使用SynchronousQueue(无容量队列),它本身不存储任务,行为上更接近“直接传递”。但配合我们的“欺骗”方案,可以提供更灵活的定制逻辑。
- 在关键业务上线前,务必进行充分的压力测试。
结语
这个文章让我深刻体会到,阅读源码并理解其设计意图的重要性。ThreadPoolExecutor通过offer方法的返回值来决定行为,这个“钩子”给了我们定制的空间。
技术没有绝对的“正确”,只有是否“合适”。在理解规则的基础上,为了特定的业务目标去谨慎地“打破”规则,并承担其后果,这正是高级工程师的职责所在。
希望这个“狡猾”但有效的技巧,能为你打开一扇思路的窗户。你会在什么场景下使用它呢?
评论区